
Langgraph: Reflection Agents
Updated:
Langgraph
Langgraph는 노드(Node)와 엣지(Edge)를 이용해 워크플로우의 흐름을 정의하여 AI Agent 애플리케이션을 빌드할 수 있는 플랫폼입니다.
- 노드(Node): 특정 작업을 수행하는 단계를 말합니다. 예를 들어, 텍스트 요약, 검색, 코드 생성 노드 등이 있습니다.
- 엣지(Edge): 노드 간의 연결을 말하며 데이터 흐름을 정의합니다. 특정 조건에 따라 분기도 가능합니다.
- 상태(State): 애플리케이션의 현재 상태를 공유하는 데이터 구조입니다.
Reflection
Reflection은 Agent의 과거 행동을 반성하고 비판해서 Agent의 품질과 성공율을 향상시킬 수 있는 프롬프팅 전략입니다.
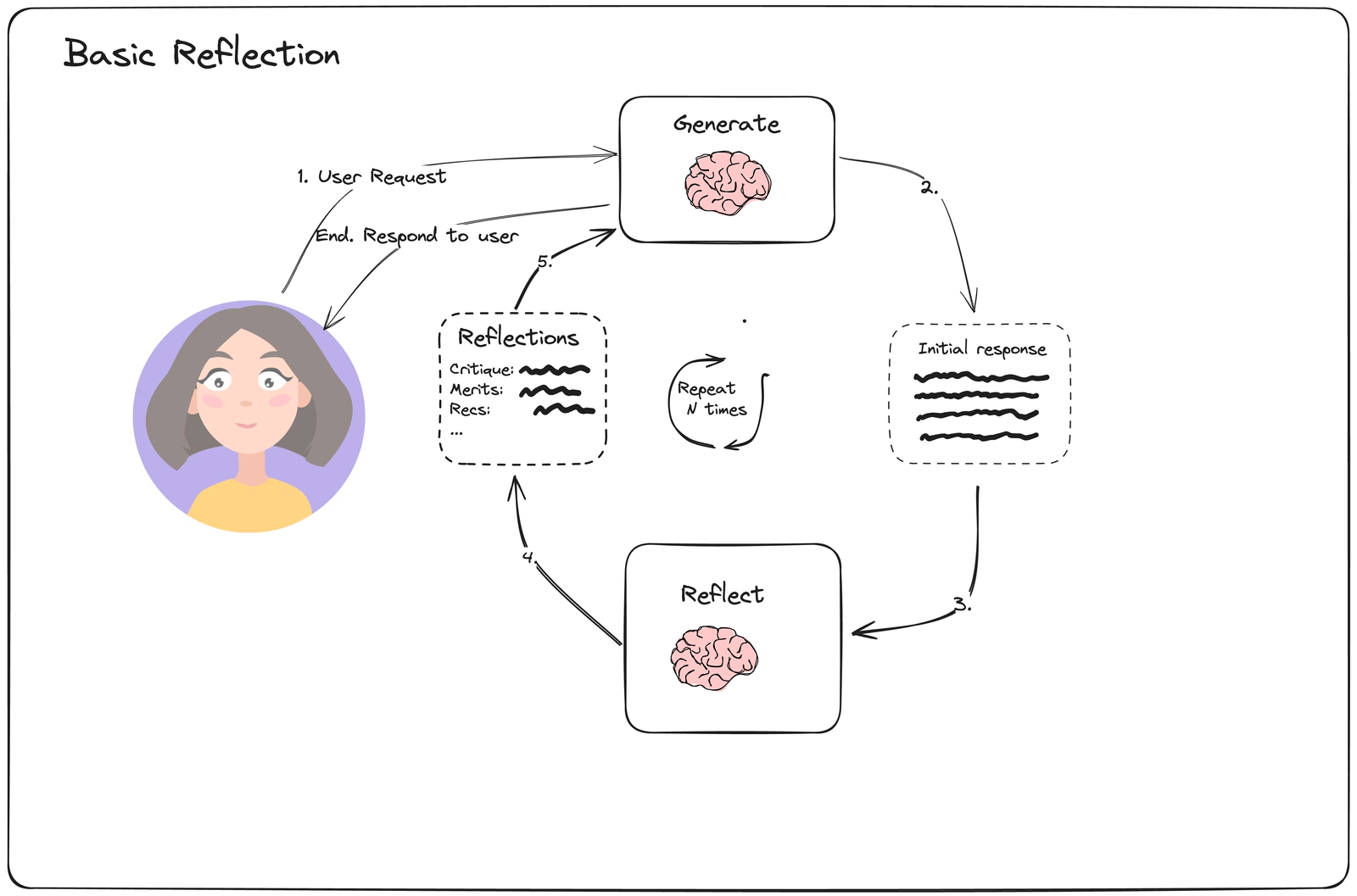
가장 간단한 Reflection 예시입니다. generator와 reflect가 있고 generator의 답변에 대해 reflect가 비판을 제공하면 generator가 비판을 근거로 삼아 다시 생성하는 루프입니다. 사용자가 지정한 루프 횟수 동안 수행되며 끝난다면 사용자에게 응답을 전달하게 합니다.
Example Application
아래는 테크 블로그의 포스트를 불러와 요약하는 Agent를 구성한 것입니다. 이 Agent는 Reflection 전략을 통해 답변을 수정해서 최종 수정본을 사용자에게 전달합니다.
workflow (plan and execution)
State
from typing import TypedDict, List
class State(TypedDict):
url: str
planning_steps: List[str]
title: str
document: str
figures: List[str]
tables: List[str]
drafts: List[str]
final_doc: str
get_document_node: 이 노드에서는 요약하고자 하는 블로그 주소에 접속하여 html을 가져오는 노드입니다. 이렇게 가져온 html은 다음 단계에서 이미지, 표를 추출하고 계획 단계로 넘어갑니다.
from langchain_community.document_loaders import AsyncHtmlLoader
from langchain_community.document_transformers import MarkdownifyTransformer
def get_document_node(state: State):
url = state.get('url')
loader = AsyncHtmlLoader(url)
docs = loader.load()
md = MarkdownifyTransformer()
converted_docs = md.transform_documents(docs)
title = converted_docs[0].metadata['title']
document = converted_docs[0].page_content
return State(title=title, document=document)
LLM: Gemini-2.0-flash 모델을 사용했습니다.
from langchain_google_genai import ChatGoogleGenerativeAI
def get_chat():
chat = ChatGoogleGenerativeAI(model='gemini-2.0-flash-001')
return chat
extract_materials: 이 단계에서는 html에서 이미지와 표 형식을 추출합니다. 여기서 추출된 자료들은 execution_node에서 사용됩니다.
def extract_materials(state: State):
print("##### Extract Materials #####")
document = state.get('document')
materials_prompt = ChatPromptTemplate([('human', extract_materials_instruction)])
chat = get_chat()
extracted_materials = materials_prompt | chat
response = extracted_materials.invoke({"document": document})
materials = response.content
figure_materials = materials[materials.find('<figures>')+9:materials.find('</figures>')].split('\n\n')
table_materials = materials[materials.find('<tables>')+8:materials.find('</tables>')].split('\n\n')
figures, tables = [], []
for figure in figure_materials:
figures.append(figure.strip())
for table in table_materials:
tables.append(table.strip())
return State(figures=figures, tables=tables)
plan_node: 이 단계에서는 html로부터 주요 포인트를 추출하고 요약합니다. 여기서 작성된 계획은 execute_node에서 자세히 서술됩니다.
def plan_node(state: State):
print("##### Plan ######")
document = state.get('document')
planner_prompt = ChatPromptTemplate([('human', plan_instruction)])
chat = get_chat()
planner = planner_prompt | chat
response = planner.invoke({"document": document})
plan = response.content.strip().replace('\n\n','\n')
planning_steps = plan.split('\n')
return State(planning_steps=planning_steps)
execute_node: 이 단계는 이미지, 표 자료를 이용해 plan_node에서 세운 계획마다 초안을 생성합니다. 가독성을 위해 구조화된 형식을 만족할 수 있는 마크다운 문법을 이용해 작성됩니다.
def execute_node(state: State):
print("##### Write (execute) #####")
document = state.get('document')
planning_steps = state.get('planning_steps')
figures = state.get('figures')
tables = state.get('tables')
write_prompt = ChatPromptTemplate([('human', write_instruction)])
text = ""
drafts = []
for step in planning_steps:
chat = get_chat()
write_chain = write_prompt | chat
result = write_chain.invoke({
"document": document,
"plan": planning_steps,
"text": text,
"STEP": step,
"figures": figures,
"tables": tables
})
output = result.content
draft = output[output.find('<result>')+8:len(output)-9]
# print(f"--> step:{step}")
# print(f"--> {draft}")
drafts.append(draft)
text += draft + '\n\n'
return State(drafts=drafts)
revise_answers: 이 단계에서 각 초안마다 reflect-revise 과정을 거쳐 얻어진 수정본을 모아 최종본을 만들어 사용자에게 전달합니다.
def get_reflect_workflow():
workflow = StateGraph(ReflectionState)
workflow.add_node("reflect_node", reflect_node)
workflow.add_node("revise_draft", revise_draft)
workflow.set_entry_point("reflect_node")
workflow.add_conditional_edges(
"revise_draft",
should_continue,
{"end": END, "continue": "reflect_node"}
)
workflow.add_edge("reflect_node", "revise_draft")
return workflow.compile()
def revise_answers(state: State, config):
print("##### revise #####")
drafts = state.get("drafts")
# 이 부분을 멀티프로세싱으로 구성하면 처리 속도를 높일 수 있습니다.
reflection_process = get_reflect_workflow()
final_doc = ""
for draft in drafts:
output = reflection_process.invoke({"draft":draft}, config)
final_doc += output.get('revised_draft') + '\n\n'
return State(final_doc=final_doc)
Define workflow
from langgraph.graph import StateGraph, END
workflow = StateGraph(State)
workflow.add_node("get_document_node", get_document_node)
workflow.add_node("plan_node",plan_node)
workflow.add_node("extract_materials", extract_materials)
workflow.add_node("execute_node", execute_node)
workflow.add_node("revise_answers",revise_answers)
workflow.set_entry_point("get_document_node")
workflow.add_edge("get_document_node","plan_node")
workflow.add_edge("get_document_node","extract_materials")
workflow.add_edge("plan_node","execute_node")
workflow.add_edge("extract_materials","execute_node")
workflow.add_edge("execute_node", "revise_answers")
workflow.add_edge("revise_answers",END)
graph = workflow.compile()
workflow (reflect)
State
class ReflectionState(TypedDict):
draft: str
reflection: List[str]
search_queries: List[str]
revised_draft: str
revision_number: int
reflect_node: execute_node에서 생성된 초안을 비판합니다. 어떤 부분이 포함되지 않았는지, 뭘 추가해야 더 나은 글이 되는지, 불필요한 부분에 대한 비평을 작성합니다. TavilySearch를 이용해 외부에서 정보를 넣어줄 수도 있습니다.
from pydantic import BaseModel, Field
from langchain_community.tools import TavilySearchResults
class Reflection(BaseModel):
missing: str = Field(description="Critique of what is missing")
advisable: str = Field(description="Critique of what is helpful for better writing")
superfluous: str = Field(description="Critique of what is superfluous")
class Research(BaseModel):
"""Provide reflection and then follow up with search queries to improve the writing."""
reflection: Reflection = Field(description="Your reflection on the initial writing for summary.")
search_queries: List[str] = Field(description="1-3 search queries for researching improvements to address the critique of your current writing.")
def reflect_node(state: ReflectionState, config):
print('##### Reflect #####')
draft = state.get('draft')
on_search = config['configurable'].get('on_search',True)
reflection = []
search_queries = []
for _ in range(2):
chat = get_chat()
structured_llm = chat.with_structured_output(Research, include_raw=True)
info = structured_llm.invoke(draft)
if not info['parsed'] == None:
parsed_info = info['parsed']
reflection = [parsed_info.reflection.missing, parsed_info.reflection.advisable]
if on_search:
search_queries = parsed_info.search_queries
break
revision_number = state.get('revision_number') if state.get('revision_number') is not None else 1
return ReflectionState(revision_number=revision_number, search_queries=search_queries, reflection=reflection)
revise_draft: reflect_node에서 작성된 비판을 기반으로 초안을 수정합니다.
def revise_draft(state: ReflectionState, config):
print("##### Revise Draft #####")
on_search = config['configurable'].get('on_search',True)
draft = state.get('draft')
search_queries = state.get('search_queries')
reflection = state.get('reflection')
content = []
if on_search:
search = TavilySearchResults(max_results=1)
for q in search_queries:
response = search.invoke(q)
for r in response:
if 'content' in r:
content.append(r.get('content'))
# print("draft: ", draft)
# print("reflection: ", reflection)
# print("search quries: ", search_queries)
# print("search results: ", content)
chat = get_chat()
revise_prompt = ChatPromptTemplate([('human',revise_instruction)])
reflect = revise_prompt | chat
result = reflect.invoke({
"draft": draft,
"reflection": reflection,
"content": content,
})
output = result.content
revision_draft = output[output.find('<result>')+8:len(output)-9]
revision_number = state.get("revision_number",1)
# print("revision draft: ", revision_draft)
return ReflectionState(revised_draft=revision_draft, revision_number=revision_number+1)
should_continue: 계속 수정해야 하는지 판단합니다. 여기서는 단순하게 수정 횟수를 기준으로 하여 기준을 넘어가면 END로 향하게 합니다.
def should_continue(state: ReflectionState, config):
print("##### should continue #####")
max_revision = config['configurable'].get("max_revision",2)
# print(f"revision: {state.get('revision_number',0)} / {max_revision}")
if state.get('revision_number') > max_revision:
return "end"
return "continue"
Run
final_state = graph.invoke({
"url":""},
config={'max_revision': 1, 'on_search': False}
)
with open('final_draft.md', 'w') as f:
f.write(final_state['final_doc'])
이 Agent를 실제로 동작하게 되면 약 2~3분정도 시간이 걸리게 됩니다. 시간을 단축하려면 reflect workflow를 multiprocessing 라이브러리를 이용해 병렬처리하도록 구성하면 빠르게 시간을 단축시킬 수 있습니다.
단순 요약, 번역과 Agent 결과의 비교
같은 원문을 번역, Gemini로 단순 요약 그리고 Reflection Agent의 요약결과를 비교해보겠습니다.
# 번역
이러한 키워드들 중에서 마지막 세트만이 사용자 의도를 정확히 일치시킵니다.
하지만 선호도는 다양한 속성에 따라 달라질 수 있습니다.
예를 들어, 소비자는 모든 비건 샌드위치를 대체 옵션으로 고려할 수 있지만, 비건이 아닌 닭고기 샌드위치는 거부할 것입니다.
식이 제한은 단백질 선택과 같은 다른 속성보다 우선하는 경우가 많습니다.
사용자에게 가장 관련성이 높은 결과만 보여주기 위해 여러 접근 방식을 사용할 수 있습니다.
DoorDash에서는 유연한 하이브리드 시스템이 우리의 요구를 가장 잘 충족한다고 생각합니다.
키워드 기반 검색 시스템과 강력한 문서 및 키워드 이해를 결합하여 비건 항목만 검색되도록 하는 것과 같은 규칙을 효과적으로 적용할 수 있습니다.
여기서는 대규모 언어 모델(LLM)을 사용하여 검색 시스템을 개선하고 소비자에게 더 정확한 검색 결과를 제공한 방법을 자세히 설명하겠습니다.
# 요약
이 중 마지막 결과만 사용자의 의도와 정확히 일치합니다.
하지만 사용자의 선호도는 속성에 따라 다를 수 있습니다.
예를 들어, 소비자는 비건 샌드위치를 대체 옵션으로 고려할 수 있지만, 비건이 아닌 치킨 샌드위치는 거부할 수 있습니다.
식이 제한은 단백질 선택과 같은 다른 속성보다 우선하는 경우가 많습니다.
DoorDash는 유연한 하이브리드 시스템이 요구사항을 충족할 가능성이 가장 높다고 판단했습니다.
키워드 기반 검색 시스템과 강력한 문서 및 키워드 이해를 결합하여 비건 항목만 검색되도록 하는 규칙을 효과적으로 적용할 수 있습니다.
본문에서는 DoorDash가 대규모 언어 모델(LLM)을 활용하여 검색 시스템을 개선하고 소비자에게 더욱 정확한 검색 결과를 제공하는 방법을 자세히 설명합니다.
# Reflection Agent
reflection: [
'LLM이 문서 및 키워드를 이해하는 데 어떻게 사용되는지에 대한 설명이 부족합니다. \
LLM의 역할과 작동 방식에 대한 자세한 설명이 필요합니다. \
또한, 검색 시스템의 성능을 평가하는 데 사용되는 지표에 대한 정보가 없습니다.',
"더 구체적인 예시를 들어주세요. \
예를 들어, LLM이 키워드 기반 검색 시스템과 어떻게 결합되어 작동하는지 설명해주세요. \
또한, '비건' 필터링 규칙 외에 어떤 규칙들이 적용될 수 있는지 예시를 들어주시면 이해도를 높이는 데 도움이 될 것입니다."
]
이 목록에서 사용자 의도와 가장 정확히 일치하는 항목은 마지막 "비건 치킨 샌드위치"뿐입니다.
사용자 선호도는 속성에 따라 우선순위가 달라질 수 있는데, 예를 들어 식이 제한은 단백질 선택과 같은 다른 속성보다 더 중요하게 여겨집니다.
따라서, 사용자에게 가장 관련성이 높은 결과만을 표시하는 것은 중요한 과제입니다.
DoorDash는 유연한 하이브리드 시스템이 이러한 요구 사항을 충족하는 데 가장 적합하다고 판단했습니다.
DoorDash는 키워드 기반 검색 시스템과 강력한 문서 및 키워드 이해 능력을 결합하여 사용자에게 더욱 정확한 검색 결과를 제공하고자 대규모 언어 모델(LLM)을 적극적으로 활용하고 있습니다.
LLM은 키워드 기반 검색 시스템의 약점을 보완하고, 검색어의 의미를 더 깊이 이해하여 사용자 의도에 부합하는 결과를 제공하는 데 핵심적인 역할을 수행합니다.
구체적으로, LLM은 다음과 같은 방식으로 활용됩니다.
첫째, LLM은 검색어와 상품 설명을 분석하여 핵심 속성들을 추출합니다.
예를 들어, "글루텐 프리 피자"라는 검색어에서 "글루텐 프리"라는 식이 제한 속성과 "피자"라는 상품 종류 속성을 추출할 수 있습니다.
둘째, LLM은 추출된 속성들을 기반으로 필터링 규칙을 적용합니다.
예를 들어, 위에서 언급한 "비건" 필터링 규칙 외에도 "매운맛" 필터링 규칙, "알레르기 유발 물질 제외" 규칙 등을 적용하여 사용자의 특정 요구 사항을 충족하는 결과를 제공할 수 있습니다.
셋째, LLM은 상품 설명의 의미를 분석하여 키워드 기반 검색 시스템이 놓칠 수 있는 관련 상품을 찾아냅니다.
예를 들어, "수제 버거"를 검색했을 때, "장인이 만든 패티를 사용한 프리미엄 버거"와 같이 유사한 의미를 가진 상품도 검색 결과에 포함될 수 있도록 합니다.
DoorDash는 검색 시스템의 성능을 평가하기 위해 다양한 지표를 사용합니다.
예를 들어, 클릭률(CTR), 검색 결과의 전환율, 사용자 만족도 조사 등을 통해 검색 결과의 관련성과 정확성을 측정합니다.
또한, AB 테스트를 통해 LLM 기반 시스템의 성능을 기존 시스템과 비교하여 개선 효과를 지속적으로 검증하고 있습니다.
이러한 노력을 통해 DoorDash는 사용자에게 더욱 만족스러운 검색 경험을 제공하고자 끊임없이 노력하고 있습니다.
번역, 요약과 달리 Reflection Agent의 구성 방식이 다른 것을 볼 수 있는데 LLM의 답변에 대해 더 나은 답변을 위한 비판을 제공하여 비판을 근거로한 답변을 재생성하는 방법입니다.
개인적으로 요약 태스크는 외부 검색을 사용하지 않는 것이 나은 결과물을 보여주는 것 같습니다. 왜냐하면 외부 정보가 계속 주입되면 글이 너무 길어지는 경우가 많이 발생했습니다. 무언가 설명이 필요한 경우(예를 들면, “Langgraph에 대해 설명해줘”)에 검색이라는 도구가 유용하다고 생각합니다.
Comments