
Apache Iceberg: Architecture
Updated:
What is a Data Lakehouse?
보통 구조화된 데이터와 구조화되지 않은 데이터를 모두 데이터 레이크에 저장한 뒤, 데이터 일부를 분석 등의 목적에 맞춰 데이터 웨어하우스에 옮기는 기존의 패러다임은 데이터의 규모가 점점 커져가면서 더 이상 유지하기 어려워지고 있습니다. 이 시스템의 한계점은 여러 개의 데이터 복사본을 저장하고, 동기화 및 일관되게 유지하며, 최신 데이터 요구사항에 맞는 빠른 데이터를 전송하는 과정에서 문제가 발생합니다. 이러한 문제를 해결하기 위해 데이터 레이크하우스라는 새로운 아키텍처가 등장했습니다.
데이터 레이크하우스는 데이터 레이크에 저장된 데이터를 데이터 웨어하우스 처럼 사용하기 위해 성능 및 편의성을 제공하는 것을 목표로 하고 있습니다.
이것이 가능하게 하는 다음의 핵심이 있습니다.
- Apache Parquet: 구조화된 데이터를 저장하고 빠르게 분석할 수 있도록 이진 열 기반 파일 포맷(Binary Columnar File Format)입니다.
- Apache Iceberg: 오픈 레이크하우스 테이블 형식은 메타데이터를 읽고 쓰기 위한 표준으로, Parquet 파일 그룹을 하나의 테이블로 일관되게 인식할 수 있게 합니다. 이를 통해 여러 Parquet 파일을 단일 데이터베이스 테이블처럼 사용할 수 있게 해줍니다.
- Open Source Catalogs (e.g., Nessie and Polaris): 데이터 레이크하우스에 있는 테이블을 추적하여 모든 도구에서 전체 데이터셋 라이브러리를 즉시 인식할 수 있습니다.
Why a data lakehouse?
데이터 레이크하우스 아키텍처로 전환하면 여러 개의 데이터 복사본이 필요하지 않다는 점에서 상당한 이점을 얻을 수 있습니다. 기존의 데이터 아키텍처에서는 운영 시스템, 데이터 웨어하우스, 데이터 마트와 같은 시스템마다 별도의 데이터 복사본을 만들어야 하는 경우가 있어 스토리지 비용이 증가하고 데이터 관리가 복잡해집니다.
- 중앙집중화된 데이터 스토리지: 하나의 저장소(데이터 레이크하우스)에서 원본 데이터를 보관하면서도 다양한 분석 및 쿼리 엔진이 직접 액세스할 수 있습니다.
- ACID 트랜잭션 및 메타데이터 관리: 일관성을 보장할 뿐만 아니라 스토리지 오버헤드를 줄여 상당한 비용을 절감할 수 있습니다.
- 다양한 도구 및 애플리케이션 접근: 각 도구 또는 애플리케이션 각자의 포맷에 맞게 데이터를 변환하고 복사했지만 레이크하우스에서는 오픈 테이블 형식을 사용하여 Spark, Presto, Trino, Pandas 같은 도구가 직접 원본 데이터에 접근할 수 있습니다. → 데이터 가공 컴퓨팅 비용이 줄어드는 추가 효과까지!
- 데이터 거버넌스 단순화: 기존의 분산된 데이터 환경에서는 각 시스템이 자체적으로 데이터 보안과 거버넌스를 관리해야 했지만 레이크하우스는 중앙에서 거버넌스를 관리할 수 있어 정책을 일관성있게 적용할 수 있습니다.
What is a Table Format?
테이블 형식은 데이터셋의 파일들을 하나의 테이블처럼 조직하는 방식입니다. 이를 통해 여러 사용자나 도구가 동시에 테이블과 상호작용할 수 있습니다.
테이블 형식의 주요 목표는 사용자가 데이터를 쉽게 다룰 수 있는 추상화 계층을 제공하고 효율적으로 관리하며 다양한 도구가 접근할 수 있도록 하는 것입니다.
The Hive Table Format
Hive는 파일 형식을 가리지 않고 파티셔닝(Partitioning)과 버킷(Bucket)을 도입하여 성능을 향상시켰으며 중앙 집중화된 메타스토어(Metastore)를 제공하여 다양한 도구들이 읽기/쓰기 작업을 수행하는데 활용할 수 있었습니다.
하지만, 파티션은 트랜잭션 스토어에 저장되므로 트랜잭션 방식으로 파티션을 추가하거나 삭제할 수 있지만 파일 추적은 파일 시스템에서 이루어지기 때문에 트랜잭션 방식으로 데이터를 추가하거나 삭제할 수 없습니다. 따라서, 일반적인 해결 방법은 파티션 수준에서 파티션 전체를 새 위치에 복사해 변경사항을 적용하고 메타스토어에서 파티션 위치를 새 위치로 업데이트하는 것입니다. 파티션이 거대하면서 해당 파티션에 작은 양의 데이터를 변경해야 할 때 이러한 방법은 비효율적입니다.
What is Apache Iceberg
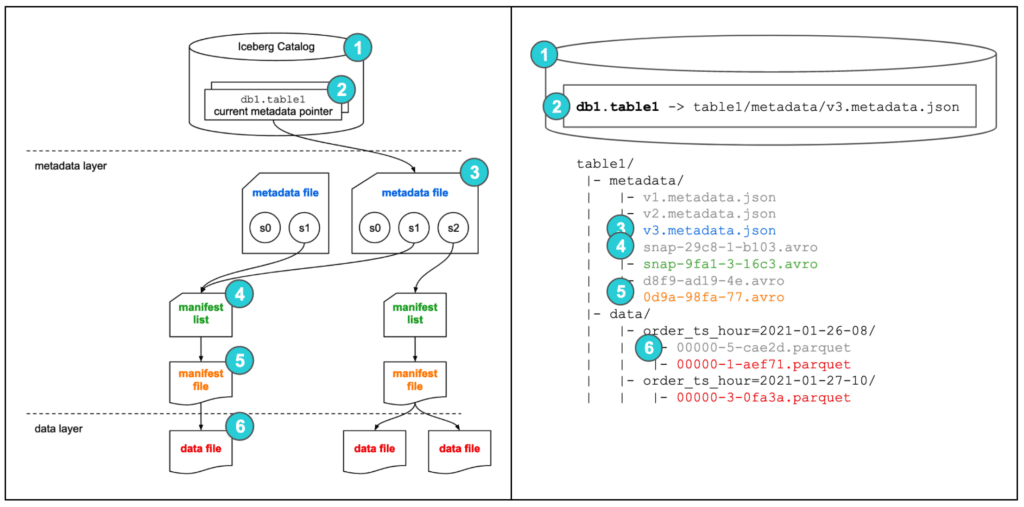
Iceberg 테이블의 아키텍처는 3개의 계층이 있습니다.
- Iceberg Catalog
- Metadata Layer: 메타데이터 파일, 매니페스트 리스트 및 매니페스트 파일을 포함
- Data Layer
Iceberg Catalog
테이블을 읽으려는 사용자가 먼저 해야 할 일은 메타데이터 포인터의 위치를 찾는 것입니다. 메타데이터 포인터의 현재 위치를 찾기 위해 중앙에 위치한 Iceberg catalog에 이동해야 합니다.
Iceberg 카탈로그의 기본 요구 사항은 현재 메타데이터 포인터를 업데이트하기 위한 연산을 지원해야 한다는 것입니다. 이것이 Iceberg 테이블의 트랜잭션이 원자적이고 정확성을 보장할 수 있는 이유입니다.
카탈로그 내에는 각 테이블마다 해당 테이블의 현재 메타데이터 파일에 대한 참조 또는 포인터가 있습니다. 예를 들어 위에 표시된 다이어그램에는 2개의 메타데이터 파일이 있습니다. 카탈로그에서 테이블의 현재 메타데이터 포인터 값은 오른쪽에 있는 메타데이터 파일의 위치입니다.
Metadata File
메타데이터 파일은 테이블에 대한 메타데이터를 저장합니다. 여기에는 테이블의 스키마, 파티션 정보, 스냅샷, 현재 스냅샷에 대한 정보가 포함됩니다.
Manifest List
매니페스트 목록은 매니페스트 파일의 목록입니다. 매니페스트 목록에는 스냅샷을 구성하는 각 매니페스트 파일에 대한 정보가 있습니다. 여기에는 매니페스트 파일의 위치, 어떤 스냅샷의 일부로 추가되었는지, 해당 매니페스트 파일이 속한 파티션에 대한 정보와 추적하는 데이터 파일의 파티션 열에 대한 하한 및 상한 정보가 포함됩니다.
Manifest File
매니페스트 파일은 데이터 파일과 각 파일에 대한 추가 세부 정보 및 통계를 추적합니다. Iceberg가 Hive 테이블 형식의 문제를 해결할 수 있게 해주는 주요 차이점은 파일 수준에서 데이터를 추적하는 것입니다.
각 매니페스트 파일은 병렬 처리 및 대규모 재사용 효율성을 위해 데이터 파일의 하위 집합을 추적합니다. 여기에는 파티션 멥버쉽, 레코드 수, 열의 하한 및 상한과 같은 데이터 파일에서 데이터를 읽는 동안 효율성과 성능을 개선하느데 사용하는 많은 유용한 정보가 포함되어 있습니다. 이러한 통계는 쓰기 작업 중에 각 매니페스트 데이터 파일 하위 집합에 대해 작성되므로 Hive의 통계보다 존재하고 정확하며 최신 상태일 가능성이 높습니다.
또한, Iceberg는 파일 형식에 독립적이므로 매니페스트 파일에도 파일 형식(Parquet, ORC, Avro 등)을 명시합니다.
A Look Under the Covers When CRUDing
CREATE TABLE
CREATE TABLE table1 (
order_id BIGINT,
customer_id BIGINT,
order_amount DECIMAL(10, 2),
order_ts TIMESTAMP
)
USING iceberg
PARTITIONED BY ( HOUR(order_ts) );
데이터베이스 db1에 table1이라는 테이블을 생성했습니다. 이 테이블은 4개의 컬럼을 가지고 order_ts 타임스탬프의 시간에 따라 파티셔닝됩니다.

위 쿼리를 실행하면 스냅샷 s0가 포함된 메타데이터 파일이 메타데이터 계층에 생성됩니다. 스냅샷 s0는 테이블에 데이터가 없기 때문에 어떠한 매니페스트 목록을 포함하지 않습니다. 카탈로그의 메타데이터 포인터는 생성된 메타데이터 파일을 가리키게 됩니다.
INSERT
INSERT INTO table1 VALUES (
123,
456,
36.17,
'2021-01-26 08:10:23'
);
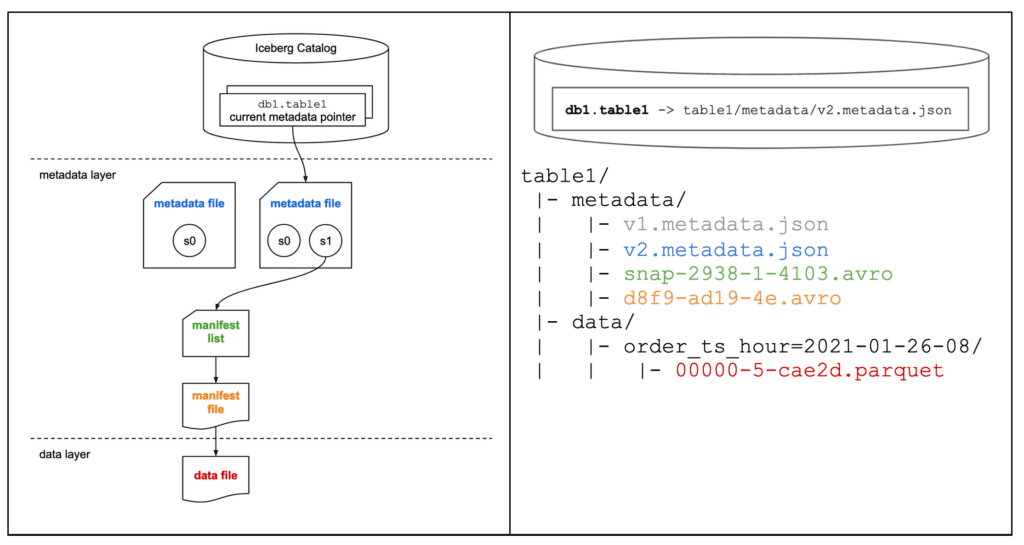
INSERT 쿼리를 실행하면 다음의 과정이 수행됩니다.
- 데이터를 포함한 Parquet 파일(
table1/data/order_ts_hour=2021-01-26-08/00000-5-cae2d.parquet)이 생성됩니다. - 데이터 파일을 가리키고 통계 및 상세 정보를 포함한 매니페스트 파일(
table1/metadata/d8f9-ad19-4e.avro)이 생성됩니다. - 매니페스트 파일을 가리키고 통계 및 상세 정보를 포함한 매니페스트 리스트(
table1/metadata/snap-2938-1-4103.avro)가 생성됩니다. - 현재 메타데이터 파일을 기반으로 하는 새로운 메타데이터 파일(
table1/metadata/v2.metadata.json)은 매니페스트 리스트를 가리키는 스냅샷 s1을 포함하고 이전 스냅샷인 s0도 유지한 채 생성됩니다. db1.table1의 현재 메타데이터 포인터가 새로운 메타데이터 파일을 가리키도록 원자성을 지키면서 업데이트됩니다.
위 5단계를 모두 거치기 전에 테이블에 접근한 사용자는 이전 메타데이터 파일을 읽게 됩니다. 이는 누구도 테이블의 일관적이지 않은 상태와 뷰를 제공하지 않는다는 의미입니다.
MERGE INTO / UPSERT
MERGE INTO table1
USING ( SELECT * FROM table1_stage ) s
ON table1.order_id = s.order_id
WHEN MATCHED THEN
UPDATE table1.order_amount = s.order_amount
WHEN NOT MATCHED THEN
INSERT *
이 쿼리는 테이블에 주문 ID가 이미 있는 경우 주문 금액을 갱신하고 없는 경우 새 주문에 대한 레코드를 삽입하는 Upsert 쿼리입니다.
이 예제에서는 테이블에 있는 주문(order_id=123)에 대한 업데이트와 2021년 1월 27일 10:21:46에 발생한 아직 테이블에 없는 새 주문에 대한 업데이트가 포함됩니다. 스테이징 테이블인 table1_stage에 업데이트할 레코드가 포함되어 기존 table1과 머지합니다.
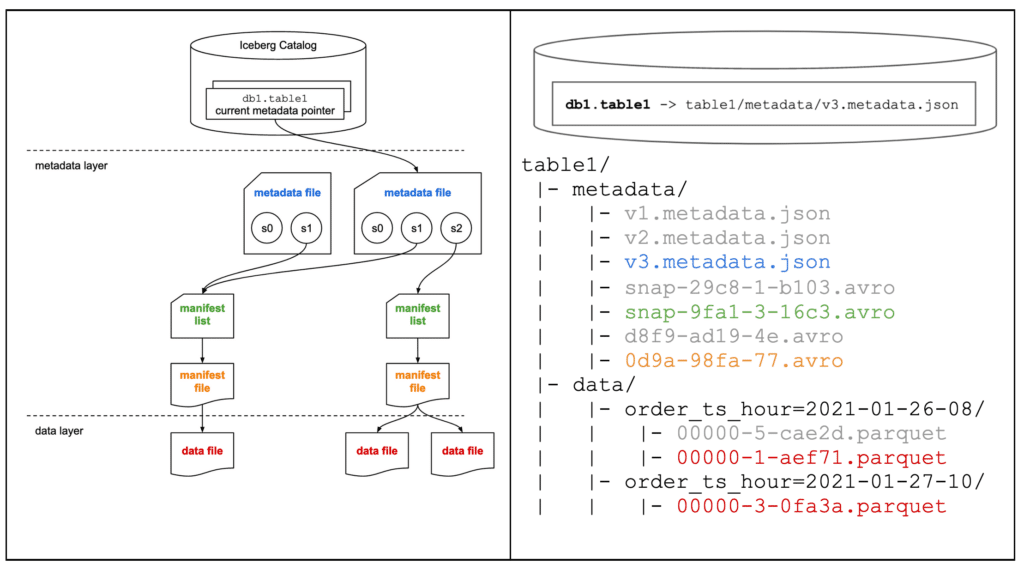
MERGE INTO를 실행할 때, 다음의 과정을 수행합니다.
table1과table1_stage에서order_id가 같은 모든 레코드를 확인합니다.- 데이터 수정 후 저장(Copy-on-Write)
order_id=123을 포함하는 기존 데이터 파일(00000-5-cae2d.parquet)이 쿼리 엔진 메모리로 로드order_id=123인 레코드를 찾아서order_amount값을table1_stage에 있는 값으로 업데이트- 업데이트된 새로운 Parquet파일(
00000-1-aef71.parquet)로 저장
파일을 통째로 다시 쓰지 않고, 변경된 데이터만 별도로 기록하는 방식 Merge-on-Read라는 방식이 현재 도입되었습니다.
table1의 어떤 레코드와도 일치하지 않는table1_stage의 레코드는 일치하는 레코드와 다른 파티션에 속하기 때문에 새로운 Parquet 파일(00000-3-0fa3a.parquet)로 작성-
두 데이터 파일을 가리키는 새로운 매니페스트 파일(
table1/metadata/0d9a-98fa-77.avro)이 생성이 예제에서는 스냅샷
s1에 있는 데이터 파일의 레코드가 변경되었으므로 매니페스트 파일과 데이터 파일을 새로 생성했습니다. 일반적으로 변경되지 않은 데이터 파일과 매니페스트 파일은 여러 스냅샷에서 재사용됩니다. - 생성된 매니페스트 파일을 가리키는 새로운 매니페스트 리스트(
table1/metadata/snap-9fa1-3-16c3.avro)가 생성됩니다. - 새로운 스냅샷
s2를 가리키고 이전 스냅샷s0,s1을 여전히 가리키는 새로운 메타데이터 파일(table1/metadata/v3.metadata.json)이 생성됩니다. db1.table1의 현재 메타데이터 포인터가 새로운 메타데이터 파일을 가리키게 합니다.
SELECT
SELECT *
FROM db1.table1
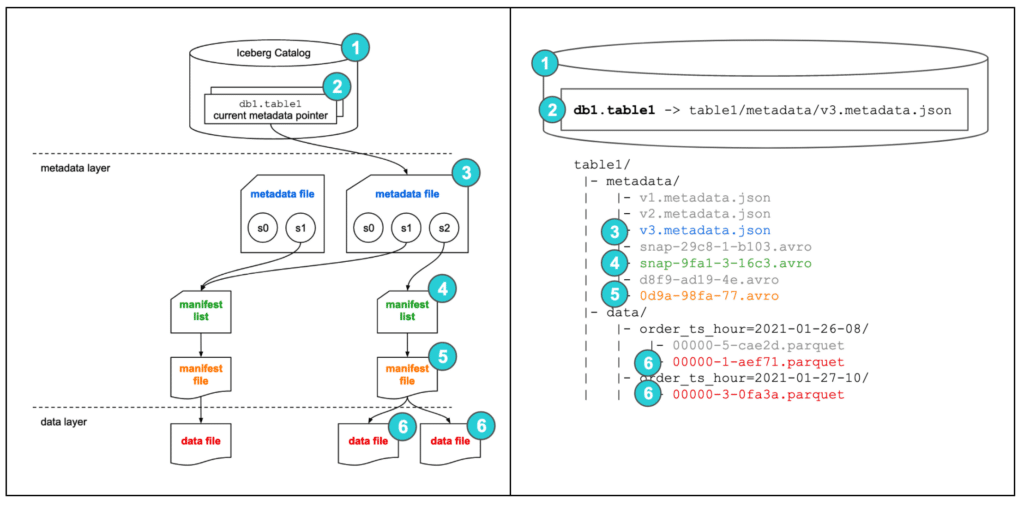
SELECT 쿼리를 실행하면 다음과 같이 실행합니다.
- 쿼리 엔진이 Iceberg catalog를 조회합니다.
- 현재 메타데이터 파일 위치를 가져옵니다.
- 메타데이터 파일을 열어 최신 스냅샷
s2의 매니페스트 리스트를 찾습니다. - 매니페스트 리스트를 열어 매니페스트 파일 위치를 찾습니다.
- 매니페스트 파일을 열어 데이터 파일 경로를 찾습니다.
- 데이터 파일을 읽고 결과를 반합니다.
Hidden Partitioning
Hive 테이블 형식의 문제 중 하나는 사용자가 쿼리 최적화를 위해 테이블의 물리적 레이아웃을 알아야 한다는 점입니다.
예를 들면, WHERE event_ts >= ‘2021-05-10 12:00:00’ 조건을 사용하면 풀스캔을 해야 하고 WHERE event_ts >= ‘2021-05-10 12:00:00’ AND event_year >= ‘2021’ AND event_month >= ‘05’ AND (event_day >= ‘10’ OR event_month >= '06') 와 같이 파티셔닝 스키마를 적용해야 느린 쿼리를 피할 수 있습니다.
SELECT *
FROM table1
WHERE order_ts = DATE '2021-01-26'
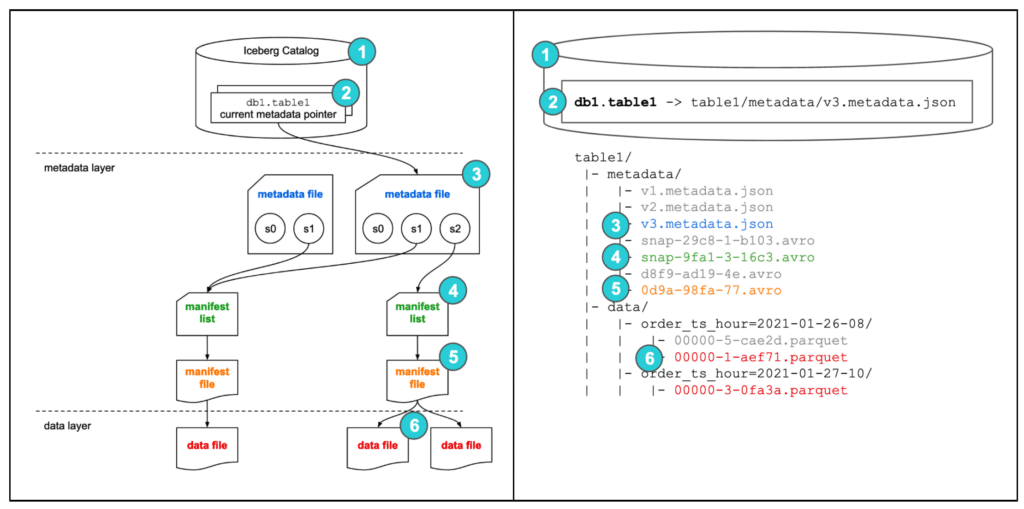
SELECT 쿼리를 실행하면 다음의 과정을 수행합니다.
- 쿼리 엔진이 Iceberg catalog에 접근합니다.
- 현재 메타데이터 파일 위치를 가져옵니다.
- 메타데이터 파일을 열어 최신 스냅샷
s2의 매니페스트 리스트를 찾고 이 매니페스트 리스트에는order_ts필드의 시간별로 파티션되어 있다는 것이 명시되어 있습니다. - 이 매니페스트 리스트를 열고 매니페스트 파일 위치를 가져옵니다.
- 매니페스트 파일을 열면, 각 데이터 파일이 어떤 파티션에 속하는지에 대한 정보가 저장되어 있기 때문에 데이터 파일이 해당 날짜의 파티션에 속하는지 비교함. 이를 이용해 2021-01-26에 해당하는 데이터 파일을 찾습니다.
- 매칭된 데이터 파일을 읽고 쿼리 결과를 반환합니다.
Time Travel
Iceberg 테이블 포맷의 또 다른 장점으로 “time travel”이라 부르는 기능이 있습니다.
거버넌스나 재현성을 위해 이전 테이블 상태를 추적하려면 특정 시점의 복사본을 생성하고 관리하는 작업이 필요했습니다. 하지만 Iceberg는 과거 다양한 시점에 테이블이 어떤 모습이었는지 바로 추적이 가능합니다.
예를 들어, 사용자가 2021년 1월 28일 시점에서 UPSERT가 되기 전의 테이블을 확인해야 한다고 가정하겠습니다.
SELECT *
FROM table1 AS OF '2021-01-28 00:00:00'
-- (timestamp is from before UPSERT operation)
SELECT 쿼리가 실행되면 다음의 과정을 수행합니다.
- 쿼리 엔진이 Iceberg catalog에 접근합니다.
- 현재 메타데이터 파일 위치를 가져옵니다.
- 메타데이터 파일을 열어 요청한 시간에 활성화된 스냅샷
s1을 찾고s1에 해당하는 매니페스트 리스트 위치를 가져옵니다. - 매니페스트 리스트를 열어 매니페스트 파일 위치를 가져옵니다.
- 매니페스트 파일을 열어 두 데이터 파일의 위치를 가져옵니다.
- 데이터 파일들을 열어 해당 시점에 존재하는 데이터를 읽어서 SELECT 쿼리의 결과를 반환합니다.
이전 매니페스트 리스트, 매니페스트 파일, 데이터 파일들이 현재 테이블 상태에서 사용되지 않지만, 아직 데이터 레이크에는 존재하고 사용가능합니다.
과거 시점의 메타데이터와 데이터 파일을 보관하는 것이 가치가 없어지는 경우 가비지 컬렉션이라는 비동기 백그라운드 프로세스를 이용해 오래된 파일을 정리할 수 있습니다. 이는 비즈니스 요구사항에 따라 적절한 세팅이 필요합니다.
Compaction
Iceberg에서 Compaction은 비동기 백그라운드 프로세스로 많고 사이즈가 작은 파일들을 적지만 사이즈가 큰 파일로 압축하는 기능입니다. 너무 많은 파일은 쿼리 엔진이 여러 파일을 읽어야 하고 파일을 여는데 필요한 메타데이터 조회 비용이 높아지게 됩니다. 따라서, 압축은 파일 수를 줄이고 쿼리 성능을 높이는데 도움됩니다.
Read-side와 Write-side 사이에는 다음의 Trade-off가 있습니다.
- Write-side: 사용자는 낮은 지연시간(Low latency)을 요구합니다. 사용자는 데이터를 빠르게 쓰고 빠르게 사용하고 싶어합니다. 극단적으로, 매 레코드를 파일로 기록하면 읽기 작업에서 조회하는데 오버헤드가 커지게 됩니다.
- Read-side: 사용자는 높은 처리량(High throughput)을 요구합니다. 단일 파일에 최대한 많은 레코드가 있어야 효율적입니다. 하지만 그 만큼 업데이트 작업에 대한 비용이 커지게 됩니다.
따라서, 쓰기 측면에서 저지연을 원한다면 파일이 너무 작아져서 작은 파일이 쌓이고 데이터를 읽을 때 성능이 떨어지게 됩니다. 읽기 측면에서 높은 처리량을 원한다면 데이터 파일 크기가 커져 새로운 데이터가 추가될 때 지연이 발생하게 됩니다.
Compaction은 이러한 트레이드 오프의 균형을 잡는데 도움을 줍니다. 사용자가 데이터를 쓰면 row format 파일이 생성되고 바로 사용 가능하게 합니다. 백그라운드 압축 프로세스가 주기적으로 이러한 작은 파일들을 열 기반 형식이며 사이즈가 크고 적은 파일로 묶게 합니다.
Comments