
데이터 파이프라인 구축해보기
Updated:
Motivation
빅데이터를 지탱하는 기술을 읽다가 데이터 엔지니어링에 사용되는 플랫폼들을 전체 파이프라인으로 구축해보고 싶어서 이 사이드 프로젝트를 진행하게 되었습니다.
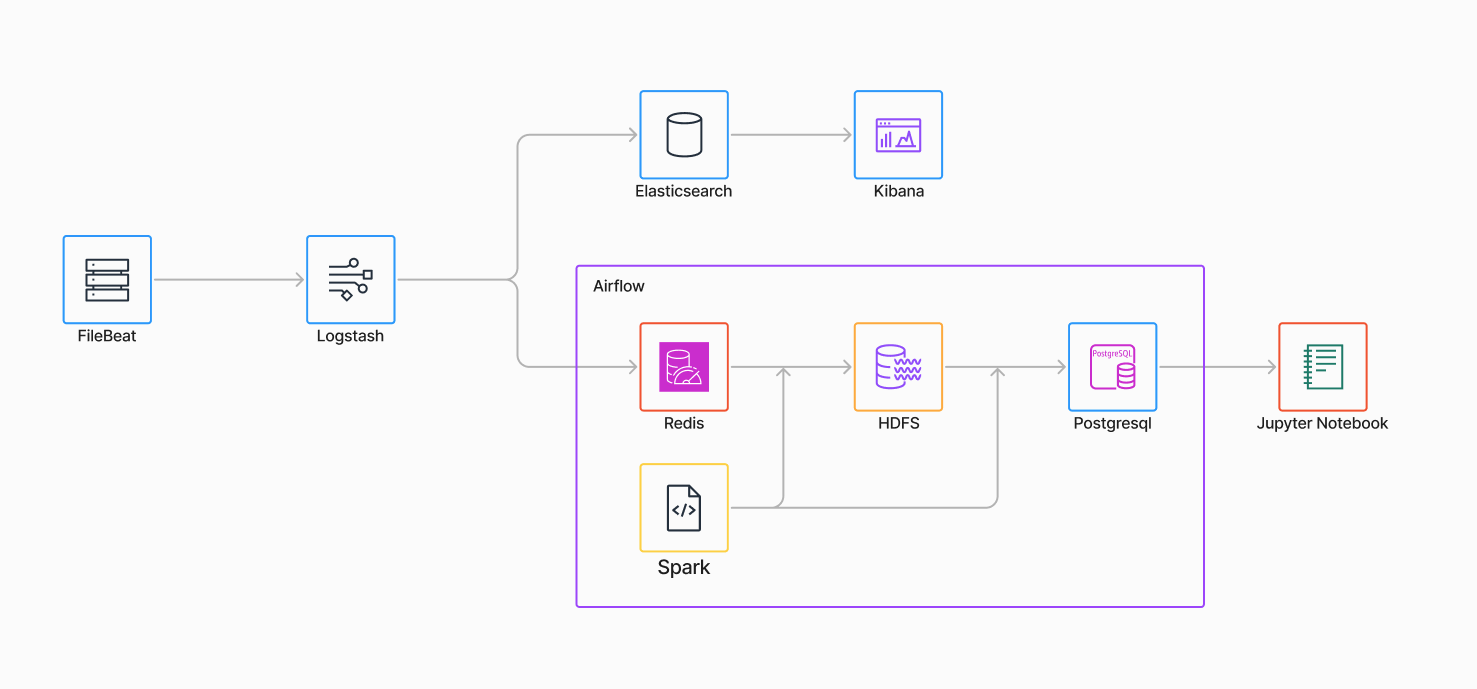
figjam으로 aws 아이콘들을 사용하여 다이어그램을 그렸습니다.
Data
먼저, 수집할 데이터는 nginx로부터 나오는 로그를 생각했습니다. 하지만 많은 양의 다양한 로그를 생산하려면 nginx로부터 나오게 하기는 어려워서 python 코드로 비슷한 nginx 로그를 생성하고 /var/log/httpd/access_log/*.log에 logging 모듈로 기록하는 방법으로 로그를 생산했습니다.
생산되는 로그는 다음과 같습니다.
206.176.215.237 - - [02/Dec/2022:18:57:34 +0900] "GET /api/items HTTP/1.1" 200 3456 477 "https://www.dummmmmy.com" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Mobile/15E148 Safari/604.1"
Producer(FileBeat)
서버 접속 기록을 로깅하는 서버에서 로그를 외부로 보내주는 무언가 필요했습니다. 로그 파일을 ELK 스택의 logstash로 읽는 방법이 있지만 Elasticsearch와 HDFS에 적재하려면 losgtash를 밖으로 빼내 수집 서버를 따로 두고 서버에는 logstash와 잘 맞는 FileBeat를 사용하는 것이 맞다고 생각했습니다.
FileBeat는 Logstash의 무겁다는 단점을 보완하여 개발된 로그 수집기입니다. /var/log/httpd/access_log/*.log 파일을 읽어 offset을 기억해 Logstash 서버로 추가되는 로그를 외부로 전달하는 역할을 합니다. FileBeat를 사용하면 Logstash에서 별다른 설정 없이 바로 사용할 수 있다는 점도 선택에 영향이 있었습니다.
Logstash
Logstash는 전달받은 로그를 Elasticsearch나 다른 곳으로 전달하는 역할을 합니다. Logstash를 사용한 이유는 람다 아키텍처같은 파이프라인을 생각하고 있기 때문입니다.
┌-- Elasticsearch -- Kibana
FileBeat -- Logstash -|
└-- HDFS ------- Postgresql
람다 아키텍처처럼 실시간으로 수집되어 보여주는 뷰와 배치 처리되어 보여주는 뷰를 제공하는 구조인데 logstash는 여러 경로의 Output을 지원하고 있기 때문에 적합하다고 생각했습니다.
logstash는 *.conf 파일을 사용하여 사용자가 원하는 데이터 가공이 가능합니다. 저는 각 항목과 ip의 위치주소, User Agent 정보를 파싱하는 필터를 넣어 파싱할 수 있었습니다. 로그를 파싱할때는 grok을 사용했고 다음과 같은 설정값을 사용했습니다. geoip와 useragent 플러그인을 사용하면 IP의 위치(국가, 도시)와 접속한 브라우저, OS 등을 추가할 수 있습니다.
filter {
grok {
match => {
"message" => "%{IPORHOST:remote_addr} - %{USER:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:method} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})\" %{NUMBER:status} (?:%{NUMBER:body_bytes_sent}|-) (?:%{NUMBER:response_time}|-) \"%{GREEDYDATA:referrer}\" \"%{GREEDYDATA:UA}\""
}
}
geoip {
source => "remote_addr"
target => "clientgeoip"
}
useragent {
source => "UA"
}
}
Elasticsearch, Kibana
Elasticsearch는 logstash로부터 전달받은 데이터를 저장하는 DB역할을 합니다. Kibana는 Elasticsearch의 데이터를 보여주는 대시보드 역할을 합니다.
FileBeat -- Logstash -- Elasticsearch -┬- Kibana
|
└- HDFS
위와 같은 파이프라인을 생각해보긴 했는데 낮은 사양의 ES 서버에 데이터 저장과 추출을 하는 것이 너무 부담되었습니다. 그래서 ES는 따로 두고 Logstash에서 HDFS로 전달하는 것으로 설계했습니다.
Dockerfile을 따로 작성하지 않았는데 Elasticsearch와 Kibana까지 도커로 올리면 맥북이 감당하지 못할 것 같아서 서버를 빌려주는 플랫폼을 알아보게 되었습니다.
처음에는 GCP 프리티어를 생각했다가 구름이 생각나서 이곳에 설치했습니다. 구름ide가 빌려주는 서버 자원이 좋지는 않지만 항상 켜둘 수 있고 *.run.goorm.io라는 도메인도 제공되어 사용하게 되었습니다.
- 만약, logstash로 구름에 있는 elasticsearch로 연결하려면 포트포워딩 세팅을 하고 port는 443으로 접근해야 합니다.
Kibana를 사용하여 대시보드를 조회할 수 있습니다.


HDFS
로그를 수집하여 배치처리하려면 먼저 저장될 공간이 필요했습니다. logstash로부터 온 데이터들은 먼저 hdfs에 저장되고 배치처리를 통해 RDB로 저장되는 과정을 생각했습니다.
하둡이 설치되는 도커를 더 늘리기는 어려워서 단일 노드로 사용하지만 설정은 분산 설정이 되어있는 모드인 Pseudo Distribute 모드로 사용했습니다.
HDFS는 특성상 파일을 여러번 수정하는데 좋지 않아 데이터를 모아 큰 파일을 한번에 적재했습니다. Logstash도 Output으로 데이터를 내보내어 중간에 저장할 공간이 필요했습니다. 저는 이 공간이 In-memory DB가 적당하다고 생각되어서 Redis를 두어 데이터를 저장하고 Spark 스크립트로 HDFS에 적재했습니다.
Redis
Logstash로부터 하루 간격의 데이터를 받아 hdfs로 한번에 적재하기 위해 logstash와 HDFS사이에 임시 데이터 저장소가 필요했습니다. 임시 공간에서 데이터 손실이 일어나지 않게 하기 위해서는 kafka를 선택하는 것이 맞습니다. kafka는 현업에서 자주 쓰이는 플랫폼이지만 broker를 관리하는 zookeeper가 추가로 설치되어야 합니다. 모든 이미지를 클라우드가 아닌 로컬에서 실행하고 있는 상황에서 도커를 추가로 올리는데 부담되어 대안으로 redis를 선택하게 되었습니다.
Logstash는 redis로 보낼때 key를 지정해야합니다. key는 그날 날짜로 지정하여 연속적으로 데이터를 redis로 전달하여 하루 간격의 배치 처리 스크립트가 실행될 때 어제 날짜로 key 접근하여 데이터를 모을 수 있었습니다.
output {
redis {
host => ["redis"]
port => 6379
data_type => "list"
key => "%{+YYYYMMdd}"
}
}
Spark
Spark는 하둡이 설치된 도커에 같이 설치했습니다. 처음에는 하둡의 Yarn의 관리를 받게 하려고 설치했지만 단일 노드로 돌리느라 local과 yarn의 차이가 나지는 않았습니다. 아래 pyspark 스크립트를 spark-submit 명령어로 실행하도록 했습니다.
Airflow
배치 스크립트를 실행하도록 Airflow를 사용했습니다. 하둡 도커에서 spark-submit을 실행하는 커맨드를 사용할 수 있도록 SSHOperator가 포함된 태스크와 hdfs에서 DB로 적재하는 배치처리하는 태스크를 구성했습니다. 데이터 양도 적고 빠르게 확인하기 위해 모두 @daily로 사용하여 하루 간격으로 실행하도록 했습니다.
spark-submit을 사용하는 스크립트는 다음과 같습니다.
ssh로 하둡이 설치된 도커로 접속하여 SSHOperator로 command를 실행하는 DAG입니다. ssh로 접속하기 위해 airflow 도커와 하둡 도커의 ~/.ssh/ 폴더를 공유시켜 하둡에서 생성된 key 파일을 airflow에서 사용할 수 있게 했습니다.
RDB로 적재하는 스크립트는 다음과 같습니다.
데이터 처리는 Pandas를 이용했습니다. Airflow 스크립트에서 데이터 처리를 하려고 했지만 Spark DataFrame을 사용하기 위해 SparkSession을 사용해야 하는데 에러 때문에 사용하지 못했습니다.(제가 잘 몰라서 그런것일 수도 있습니다.) HDFS에서 parquet 파일을 가져와 pyarrow를 이용하여 pandas DataFrame으로 변환하여 데이터 처리를 수행했습니다.
transform() 과정에서 df_yesterday와 df_today 데이터프레임으로 나누는 코드가 존재합니다. 이것은 logstash가 UTC로 동작하기 때문입니다. 기록되는 날이 UTC 기준이라서 한국 시간과 9시간 차이가 나기 때문에 Redis에 같은 키에 다른 날짜의 로그가 들어오게 됩니다.
예를들면, UTC 2022-11-30의 데이터는 KST기준 2022-11-30 09:00:00부터 2022-12-01 08:59:59까지이므로 Redis에는 20221130키로 접근했을 때 2022-11-30 데이터와 2022-12-01 데이터가 들어와 있게 됩니다. 따라서 이를 나눠 DB에 적재하는 코드가 필요했습니다. DB에 나눠 적재하지 않으면 배치 처리할때 그 이전 날짜들의 테이블까지 모두 조회해야할 가능성이 있기 때문에 이를 방지하는 이유또한 있습니다.
airflow에 SparkSession으로 세션을 생성하면 30초의 timeout으로 DAG가 등록되지 않았습니다.(정확한 이유가 맞는지는 잘 모르겠습니다.) 그래서 SparkContext를 통해 hdfs에 접근하는 방법으로 배치 파일을 구성했습니다.
PostgreSQL, Jupyter Notebook
RDB로 PostgreSQL을 사용했습니다. PostgreSQL을 MySQL보다 자주 사용해서 익숙하기 때문에 선택했습니다. BI로 Jupyter Notebook을 사용했는데 똑같이 Apache Zeplin보다 익숙하기 때문에 선택했습니다.
Jupyter Notebook은 로그인 시 패스워드를 물어보지 않게 하면 토큰을 입력해야 하는데 Notebook 접속 시 Jupyter Notebook 도커의 로그에 있는 URL로 접속해야 하는 불편함이 있습니다.
Comments