
RAG: Hybrid search + Reranker
Updated:
RAG
RAG (Retrieval Augmented Generation)란, LLM이 학습한 데이터로부터 답변하지 않고 외부 문서(Context)를 참조할 수 있도록 하는 시스템을 말합니다. RAG는 LLM이 자신이 학습한 데이터가 아닌 외부의 최신 정보를 참조하여 답변의 부정확성이나 환각(Hallucination)을 줄일 수 있습니다.
Retriever
Retriever는 유저의 질문에 관련이 높은 문서를 가져오는 역할을 담당하는 구성요소입니다. 관련 문서를 가져오는 전략으로는 BM25, Bi-Encoder 등의 방식이 있습니다.
Lexical Search: BM25
BM25는 키워드 매칭을 통해 점수를 내는 방식을 말합니다. TF-IDF를 활용해 질의와 문서간의 유사도를 계산하여 빠르고 간단한 질문에 적합합니다. 하지만, 질의의 문맥을 이용하지 못해 관련되지 않은 문서가 검색되는 경우도 있습니다.
Semantic Search: Bi-Encoder
Bi-Encoder는 질의와 문서간의 임베딩 벡터 유사도를 계산하여 점수를 내는 방식입니다. BERT와 같은 언어모델을 이용해 문맥적 의미가 담긴 임베딩 벡터를 생성하여 질의와 문서의 의미적인 유사성을 잘 찾아낼 수 있습니다. 미리 벡터로 변환하여 저장할 수 있어 검색 시 유사도만 계산하면 되므로 크게 느리지 않습니다. 하지만, 질의나 문서가 길어질수록 벡터로 표현할 때 정보가 손실될 수 있고 Query와 Candidates간의 관계성을 고려하지 않기 때문에 Cross-Encoder 대비 정확도가 떨어집니다.
Hybrid Search: Lexical Search + Semantic Search
Hybrid Search는 유저 질의의 키워드를 중점으로 찾는 BM25와 유저 질의와 의미적으로 유사한 문서를 찾는 Bi-Encoder를 같이 사용하는 방법을 말합니다. Hybrid Search의 검색 결과는 Lexcial Search 혹은 Semantic Search를 단독으로 사용한 결과보다 정확한 문서를 검색할 수 있습니다. 검색 결과에 가중치를 부여하면 도메인 특성에 따라 최적화할 수 있습니다. 보통 자주 사용하는 계산방식으로는 CC(Convex Combination)과 RRF(Reciprocal Rank Fusion)이 있습니다.
Convex Combination
- $score(doc) = \alpha * score_{lex}(doc) + \beta * score_{sem}(doc)$
CC는 alpha와 beta을 각각 스코어에 곱해 최종 스코어를 계산하는 방식입니다. 두 스코어 값을 합치기 위해 각 스코어마다 Normalization 과정이 필요합니다.
Reciprocal Rank Fusion
- $score(doc) = \frac{1}{k + rank_{lex}(doc)} + \frac{1}{k + rank_{sem}(doc)}$
RRF는 가중치가 아닌 문서의 순위를 이용하는 방식입니다. 가중치를 이용하지 않기 때문에 Normalization 과정이 필요하지 않고 k는 순위가 낮은 문서를 위해 조정하는 임의의 값입니다.
Cross-Encoder
Cross-Encoder는 하나의 언어모델에 Query와 Candidate를 같이 넣어 유사도를 계산하는 방식입니다. Bi-Encoder 대비 예측 성능이 괜찮지만 Cross-Encoder를 Retreiver로 사용한다면 매 질의마다 모든 문서와의 유사도를 계산해야 하기 때문에 단독으로 사용하기 어렵습니다.
Reranking 전략
Reranking 전략은 적절한 문서 후보군을 선별하고 Cross-Encoder로 순위를 재조정하는 전략을 말합니다. 이렇게 구성하면, Cross-Encoder만 사용했을 때보다 계산 비용이 줄고 정확도를 확보할 수 있는 방법입니다.
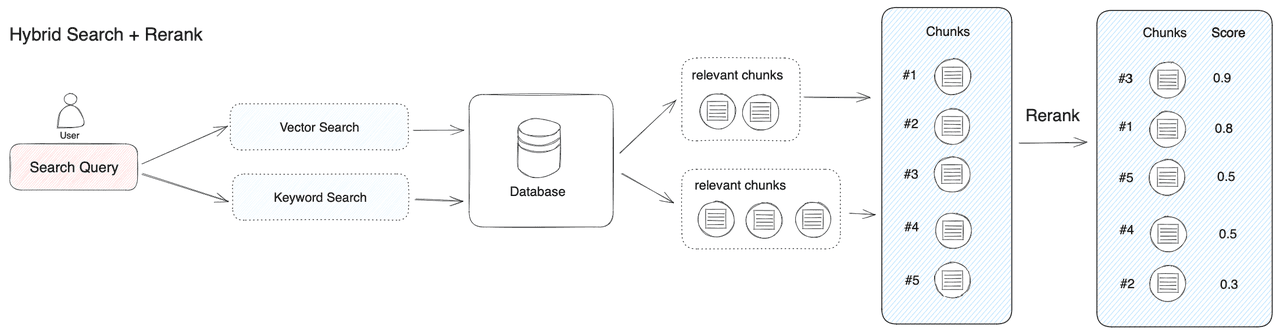
그렇다면 RAG 시스템에서 Reranking 전략이 왜 필요한지 생각해볼 수 있는데 LLM의 답변 정확도가 Context의 순서와 관계가 있기 때문입니다. Lost in the Middle: How Language Models Use Long Contexts 논문에는 정답과 관련된 문서가 가운데 위치할 수록 답변 성능이 떨어지는 것을 확인할 수 있습니다. 따라서, 이러한 이유 때문에 RAG 시스템에서 Hybrid Search의 문서 순위를 재조정하는 Reranking 전략이 필요함을 알 수 있습니다.
RAG 구현
Pipeline
RAG 파이프라인 순서는 다음과 같습니다.
- 유저가 질문을 보내면
text-embedding-004모델로부터 임베딩 벡터를 받습니다. - 유저 쿼리와 임베딩 벡터를 이용해 Vector Store인
Opensearch에 Hybrid Search로 후보 문서들을 가져옵니다. - 후보 문서들을 Opensearch ML 기능을 이용해 Reranking합니다.
- 최종 Context와 유저 질의를 LLM(
Gemini-2.0-flash)에 전달해 답변을 받아옵니다. - LLM의 답변을 유저에게 전달합니다.
Opensearch
Vector Store로 Opensearch를 선택했는데 그 이유는 lexical search와 semantic search 모두 지원하기 때문입니다. Semantic search는 knn(K-Nearest Neighbor) 알고리즘을 지원하고 있어 빠른 검색 결과를 받아볼 수 있습니다. 또한, Opensearch 클러스터에 ML모델을 배포하고 REST API로 사용할 수 있는 기능이 있어 이를 이용해 Reranking 전략을 사용할 수 있었습니다.
Gemini
LLM은 Google의 Gemini 모델을 선택했습니다. 그 이유는 1M의 토큰 컨텍스트를 지원하고 있어 프롬프트에 충분히 많은 Context들을 넣을 수 있다는 장점이 있기 때문입니다.
Gemini 2.0 Flash의 무료 등급은 시간당 1백만개의 토큰 제한이 걸려있고 제품 개선에 사용 됩니다.
Demo APP
많이 사용하는 프레임워크인 Streamlit을 사용해서 앞단을 구성했습니다.
사용자가 PDF파일을 업로드하면 파싱 후 Vector Store에 문서를 적재하고 아래 조건에 따라 유저 질의에 따라 문서를 가져올 수 있도록 구성했습니다.
PDF Parse
PDF 문서 내에서 정보를 추출하는 라이브러리 중 하나인 Unstructured를 이용했습니다. 하지만, PDF의 표를 추출하는 과정에서 문제가 발생했습니다.
Llamaindex
PDF 문서를 Unstructured 라이브러리로 바로 파싱하는 경우, 테이블 형식이 제대로 파싱되지 않는 문제가 발생했습니다. 이를 해결하기 위해 중간 변환 과정이 필요했고 마크다운과 이미지 형식 두 가지를 고려했습니다. 이미지 변환 방식도 LLM이 이미지도 잘 해석해주기 때문에 가능한 방법이지만 그 만큼 비용이 들어가기 때문에 마크다운 변환을 선택하게 되었습니다. 마크다운 변환을 이용할 때는 Llamaindex라는 상용 서비스를 이용했고 괜찮은 결과물을 반환해주었습니다.
Llamaindex의 Free Plan은 하루에 1000페이지 변환이 가능합니다.
Llamaindex 말고도 Upstage에서도 Document Parse 서비스를 제공중에 있습니다.
import os
from llama_cloud_services import LlamaParse
llamaparse = LlamaParse(
result_type="markdown",
api_key=os.environ.get('LLAMA_CLOUD_API_KEY')
).load_data(filepath)
Unstructured.io
Llamaindex로 변화된 마크다운들로부터 정보를 추출해야 합니다. Langchain에서 제공하는 UnstructuredMarkdownLoader를 이용해 문서를 파싱하고 Vector Store에 저장할 준비를 합니다.
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader(
file_path=markdown_path,
mode="elements",
chunking_strategy="by_title",
strategy="hi_res",
max_characters=4096,
new_after_n_chars=4000,
combine_text_under_n_chars=2000,
)
docs = loader.load()
여기서 추출된 테이블은 벡터 스토어에서 검색할 때 좋지 못하므로 LLM을 이용해 테이블 내용을 요약하도록 하고 요약된 설명을 검색에 활용하도록 합니다.
OpenSearchVectorSearch
Langchain에서 Opensearch를 벡터 스토어로 사용할 수 있도록 구현체를 제공합니다. 이 클래스를 이용하면 docs를 쉽게 Opensearch에 적재할 수 있습니다. OpenSearchVectorSearch의 embedding_function에는 embedding 모델을 넣어 Semantic search를 위해 문서의 임베딩 벡터를 추가합니다.
단, Opensearch에 문서들을 적재하기 전에 반드시 인덱스를 생성해야 합니다.
import os
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import OpenSearchVectorSearch
llm_emb = GoogleGenerativeAIEmbeddings(
model='models/text-embedding-004',
google_api_key=os.environ.get('GOOGLE_API_KEY')
)
vector_db = OpenSearchVectorSearch(
index_name=index_name,
opensearch_url=opensearch_url,
embedding_function=llm_emb,
http_auth=(opensearch_id, opensearch_password),
use_ssl=True,
verify_certs=False,
is_aoss=False,
engine="faiss",
space_type="l2",
bulk_size=100000,
timeout=60,
ssl_show_warn=False
)
vector_db.add_documents(
documents=docs,
vector_field='vector_field',
bulk_size=100000,
)
Retrievals
Opensearch를 이용할 수 있는 Python 라이브러리인 opensearchpy를 사용할 수 있습니다. 라이브러리를 이용해 lexical search와 semantic search를 구현하고 이를 이용해 hybrid search를 구현합니다.
from opensearchpy import OpenSearch
client = OpenSearch(
hosts,
...
)
def get_document(query, index_name):
response = client.search(body=query, index=index_name)
return response
def get_lexical_search(**kwargs):
index_name = kwargs.get("index_name")
query = {
"query": {
"match": {
"text": {
"query": f"{kwargs.get('query')}"
}
}
},
"size": kwargs.get("k")
}
response = get_document(query, index_name=index_name)
return response
def get_semantic_search(**kwargs):
index_name = kwargs.get("index_name")
query = {
"query": {
"knn": {
"vector_field": {
"vector": kwargs.get("vector"),
"k": kwargs.get("k")
}
}
}
}
response = get_document(query, index_name=index_name)
return response
각 search 함수의 response에는 문서와 스코어가 튜플 형태로 저장되어 있습니다. 스코어를 normalization하는 함수와 CC 혹은 RRF를 적용하는 함수를 작성하여 최종 문서를 반환하도록 합니다.
def normalization(response):
hits = response['hits']['hits']
max_score = response['hits']['max_score']
for hit in hits:
hit['_score'] = float(hit['_score']) / max_score
response['hits']['max_score'] = hits[0]['_score'] # 1.0
response['hits']['hits'] = hits
return response
def get_ensemble_results(doc_lists: List[List[Document]], weights, k=60):
# Weighted RRF
# 동점자 처리에 가중치를 주는 것으로 해결할 수 있습니다
documents = set() # unique docs
content_to_document = {}
for doc_list in doc_lists:
for (doc, _) in doc_list:
documents.add(doc.page_content)
content_to_document[content] = doc
results = {content: .0 for content in documents}
for doc_list, weight in zip(doc_lists,weights):
for rank, (doc, _) in enumerate(doc_list,start=1):
content = doc.page_content
score = weight * (1 / (rank + k))
results[content] += score
sorted_results = sorted(results.items(), key=lambda x: -x[1])
sorted_docs = [
(content_to_document[content], score) for (content, score) in sorted_results
]
return sorted_docs
Rerank를 수행할 때는 opensearchpy의 REST API를 따로 호출하도록 구현했습니다.
def rerank_documents(query, retrievals: List[Tuple[Document, float]]):
model_id = "" # Opensearch Rerank Model id
text_docs = [doc.page_content for doc, _ in retrievals]
payload = {
"query_text": query,
"text_docs": text_docs
}
response = client.transport.perform_request(
method="POST",
url=f"/_plugins/_ml/models/{model_id}/_predict",
body=payload,
)
response = response['inference_results']
return response
Question Answering
QA 단계에서는 Retriever가 가져온 문서와 유저 질문을 묶어 프롬프트를 구성하여 답변을 받아오면 됩니다. ChatGPT처럼 한글자씩 나타나도록 하고 싶다면 아래 코드처럼 stream을 사용하여 generator 함수로 구성하면 됩니다.
from langchain.schema import StrOutputParser
from langchain_core.prompts import HumanMessagePromptTemplate, SystemMessagePromptTemplate, ChatPromptTemplate
from langchain_google_genai import GoogleGenerativeAI
def get_answer(**kwargs):
instruction = '' # system prompt
human_prompt = '' # user prompt
system_template = SystemMessagePromptTemplate.from_template(instruction)
human_template = HumanMessagePromptTemplate.from_template(human_prompt)
prompt = ChatPromptTemplate.from_messages([system_template, human_template])
invoke_args = {} # user prompt의 f-string 요소가 있다면 해당 위치에 값을 넣을 수 있습니다
chain = prompt | llm | StrOutputParser()
response = chain.stream(invoke_args)
for chunk in response:
yield chunk
RAG Demo app
아래 이미지처럼 검색 시 어떤 문서를 참조했는지 확장탭을 넣어 확인할 수 있도록 구현했습니다.
아래 이미지처럼 정보를 찾을 수 없는 경우에는 관련된 내용이 없다는 답변을 받게 됩니다. 주어진 컨텍스트에는 미국채 10년만 있는데 쿼리에는 미국채 1년을 물어보고 있어 찾을 수 없다는 원했던 답변이 제대로 출력되었습니다.
Problem
예상하지 못했던 문제입니다. PDF로부터 정보를 추출할 때, 표의 형식이 마크다운으로 표현하지 못하는 경우 문제가 발생했습니다. 예를 들어, 다음 이미지와 같이 헤더부분이 나뉘어 있는 경우 마크다운으로 제대로 표현하지 못했습니다.
이런 테이블 형식이라면 이미지 변환 방식이 필요하겠다는 생각을 했습니다. 여기에는 적용하지 않고 마크다운으로 변환된 테이블을 사용했지만 프로덕션 환경에서 사용할 때는 이미지로 변환하는 것도 고려할 필요가 있다고 생각됩니다.
Comments