
Spark on Kubernetes
Updated:
Apache Spark
Spark는 대규모 데이터 처리를 위한 분석 엔진입니다. Java, Scala, Python 등의 언어를 지원하고 정형 데이터를 처리할 수 있는 SparkSQL, 머신러닝을 위한 MLlib, 스트리밍 처리를 위한 Spark Streaming 등을 포함한 많은 기능을 지원합니다.
Spark on Kubernetes
Apache Spark의 애플리케이션은 기본적으로 YARN, Mesos 등의 리소스 매니저에 의해 관리됩니다. 하지만, Spark 버전 2.3부터 쿠버네티스를 리소스 매니저로 사용할 수 있도록 지원하고 있습니다.
Spark on Kubernetes는 Kubernetes 클러스터에 Spark 클러스터를 구성하고 실행하는 방식을 말합니다. 즉, Spark의 Driver와 Executor를 Pod로 띄우는 구조입니다.
이 방식의 장점으로는 인프라 관리에 있습니다. Spark 클러스터와 쿠버네티스 클러스터 모두 관리해야 하는 인프라팀에게 부담을 줄여줄 수 있고 리소스 부족시에도 쿠버네티스의 Autoscaling을 기대할 수 있습니다.
How it works
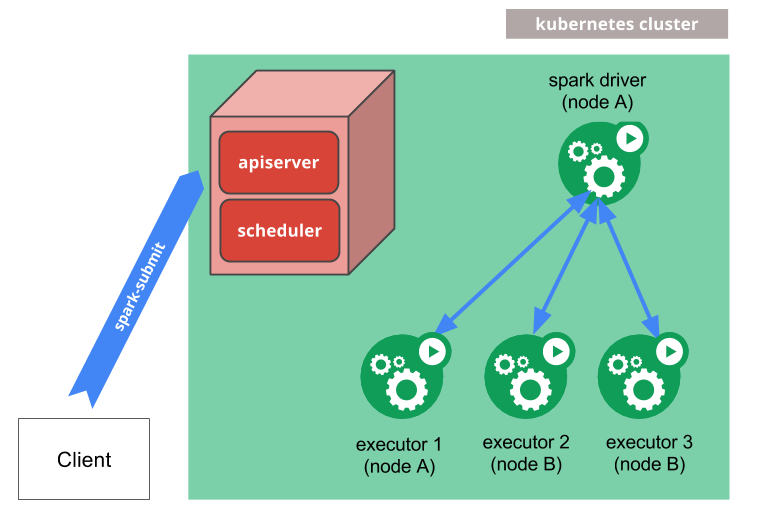
spark-submit을 실행하면 쿠버네티스 클러스터에 Spark driver pod 생성을 요청합니다.- 이때 어떤 이미지를 사용할 것인지(
spark.kubernetes.container.image), 어떤 네임스페이스에 띄울 건지(spark.kubernetes.namespace), 필요한 권한이 있는지(spark.kubernetes.authenticate.driver.serviceAccountName)를 필요로 합니다.
- 이때 어떤 이미지를 사용할 것인지(
- 클러스터에 Driver Pod가 실행되면 이후 Executor Pod들을 쿠버네티스 API로 요청하여 띄웁니다.
- Executor Pod가 생성되면 Pod끼리 클러스터 네트워크를 통해 통신하여 사용자 애플리케이션을 실행합니다.
- 애플리케이션 실행이 완료되면, Executor Pod들은 종료되며 제거됩니다. Driver Pod가 제거되기 전까지는 completed 상태를 유지하고 있으며 로그를 그대로 보존하게 됩니다.
또한, node selector, affinity/anti-affinity를 설정해서 Spark가 데이터 처리에 적절한 자원에 스케줄링되도록 설정할 수 있습니다.
Deploy Mode
Spark의 배포 방식은 Driver가 client에서 실행되는 Client 모드 혹은 cluster에서 실행되는 Cluster 모드가 있습니다.
Client Mode
Driver가 spark-submit을 실행한 클라이언트에서 실행되는 모드입니다. Driver는 Cluster Manager(YARN, Kubernetes 등)에 Executor 할당을 요청하고 배치된 Executor는 클러스터의 노드에 분산 배치되어 작업을 수행합니다.
이 모드는 Driver의 로그를 로컬에서 확인할 수 있기 때문에 Jupyter나 Zeppelin과 같이 대화형 개발/테스트에 적합합니다.
Cluster Mode
Driver가 클러스터 내부(Kubernetes, YARN 등)에 Executor와 같이 배포되어 실행되는 모드입니다. spark-submit을 하면 Cluster Manager에 애플리케이션을 제출하고 Cluster Manager가 클러스터에 Driver가 배치시킵니다. 다시 Driver는 Executor 할당을 요청하여 배치된 Executor들이 작업을 수행합니다.
이 모드는 클라이언트와 분리되어 있고 클러스터 자원을 활용하는 방식이기 때문에 프로덕션 환경에 적합합니다.
Spark on Kubernetes
Spark on Kubernetes에도 Client 모드와 Cluster 모드를 지원합니다.
Client 모드는 클라이언트에서 Driver가 실행되며 Driver가 쿠버네티스에 Executor 할당을 요청하고 배치된 executor가 작업을 수행하는 방식입니다.
Client 모드는 Spark 2.4.0 이후부터 지원합니다.
Cluster 모드는 쿠버네티스 API를 통해 Driver 배치를 요청하고 Driver가 다시 Executor 할당을 요청하여 배치된 Executor가 작업을 수행하는 방식입니다.
Client/Cluster 모드 모두 쿠버네티스에 Pod 생성 요청을 하기 때문에 파드 생성/제거 등의 권한을 가진 serviceAccount 설정이 필요합니다.
ServiceAccount
Spark on Kubernetes를 구성하기 위해서는 쿠버네티스의 일부 권한이 부여된 serviceAccount가 필요합니다. Role과 RoleBinding 또는 ClusterRole과 ClusterRoleBinding을 생성하기 위해 아래 선언을 수행합니다.
Role은 특정 네임스페이스에서만 적용되지만 ClusterRole은 클러스터 전체에 적용됩니다.
kubectl create serviceaccount spark-sa
kubectl create clusterrolebinding spark-role \
--clusterrole=edit \
--serviceaccount=default:spark \
--namespace=default
--clusterrole=edit은 대부분의 object의 read/write 권한을 부여합니다.
위의 ClusterRoleBinding의 nameapsce는 같은 이름이 있거나 하는 등의 관리 측면에서 namespace별로 관리하고 싶을 때 사용합니다.
또는 아래 yaml파일을 적용합니다. 아래 Role과 RoleBindding을 ClusterRole과 ClusterRoleBinding으로 바꾸면 클러스터 전체로 적용가능합니다.
# spark-sa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark-sa
namespace: spark
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: spark-ns-role
namespace: spark
rules:
- apiGroups: [""]
resources: ["pods", "pods/log", "pods/exec", "services", "configmaps", "secrets", "events", "persistentvolumeclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["create", "delete", "get", "list"]
- apiGroups: [""] # ClusterRole인 경우 필요없음
resources: ["namespaces"]
verbs: ["get", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spark-ns-role-binding
namespace: spark
subjects:
- kind: ServiceAccount
name: spark-sa
namespace: spark
roleRef:
kind: Role
name: spark-ns-role
apiGroup: rbac.authorization.k8s.io
kubectl apply -f spark-sa.yaml
Example
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("jupyter") \
.master("k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port>") \
.config("spark.submit.deployMode", "cluster") \
.config("spark.executor.instances", "2") \
.config("spark.kubernetes.container.image", "bitnami/spark:3.5.0") \
.config("spark.kubernetes.namespace","spark") \
.config("spark.kubernetes.authenticate.driver.serviceAccountName","spark-sa") \
.config("spark.executor.memory", "512m") \
.config("spark.executor.cores", "1") \
.config("spark.driver.memory", "512m") \
.config("spark.executorEnv.LD_PRELOAD", "/opt/bitnami/common/lib/libnss_wrapper.so") \
.config("spark.pyspark.python", "/usr/bin/python3") \
.config("spark.pyspark.driver.python", "/usr/bin/python3") \
.getOrCreate()
만약, Jupyter Notebook과 같은 대화형 도구에서 사용하고 싶다면
spark.submit.deployMode를 client로 설정해야 합니다.
Client 모드에선 Driver와 Executor의 python 버전과 Spark 버전이 일치해야 합니다. bitnami/spark:3.5.0의 python은 3.11을 사용하고 있으므로 client의 python 버전도 3.11로 맞춰주어야 합니다.
쿠버네티스의 apiserver url을 알고 싶다면
kubectl cluster-info를 실행하면 알 수 있습니다.
또는 spark-submit 명렁어를 통해서도 가능합니다.
spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name jupyter \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.container.image=bitnami/spark:3.5.0 \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sa \
pyspark.py
실행하게 되면 deploy 모드와 관계없이 쿠버네티스에 executor pod가 띄어지는 것을 볼 수 있습니다.
아래 이미지는 Client 모드로 Spark를 실행하여 Executor Pod들이 쿠버네티스에 띄어진 모습입니다. 만약, Cluster 모드로 실행한다면 Driver, Executor들이 같은 곳에 배포되어 있어야 합니다.
Comments